
Over the last six months, we kept seeing the same pattern in the Software Development Lifecycle (SDLC). Different companies, different stacks, same outcome: plenty of data, no clear answers.
Leadership asks simple questions:
Why are we late?
Where is the risk?
What should we fix?
But the answers still come back as explanations rather than facts, because the data doesn’t add up to a coherent view of the process. What’s missing is context.
Most organizations believe they’re one layer away from understanding their SDLC. If they centralize the data, clean it up, and put a dashboard on top, the truth will emerge.
It doesn’t.
SDLC data wasn’t designed to explain the process. It was designed to track activity inside tools. Each system tells its own version of the story, and none of them agree.
So teams step in to reconcile it. They build spreadsheets, ingest it into BI tools, assemble decks, and tell a story that sounds plausible enough to move forward. By the time it’s presented, it’s already outdated and still shaped by human interpretation.
We’ve normalized this. We shouldn’t have.
There’s an assumption that AI will finally make sense of all this data. And in the agentic world, where AI is contributing to specifications, actively writing code, routing work, and making decisions, the stakes are even higher. If your data can’t tell a coherent story, your agents can’t act on one.
The problem runs deeper than bad data. Most teams start by building dashboards on top of their data and hoping the right insights fall out. The same pattern plays out with AI: teams add agents before the process itself is legible.
An agent tasked with helping ship a feature faster needs to know what was agreed in the spec, what changed since, where work is stuck, and which constraints are non-negotiable. Without that, it produces output that looks right and still causes problems downstream.
This is where most teams get stuck. The data reflects activity inside tools, not how work actually flows from idea to delivery.
So the problem isn’t that teams start with analysis. It’s that the data was never structured to answer the questions that actually matter—for humans or for agents.
The right starting point is representation. Before you ask what insights you can extract, or what your agents can act on, you have to ask whether your data actually represents how work happens. For most companies, it doesn’t.
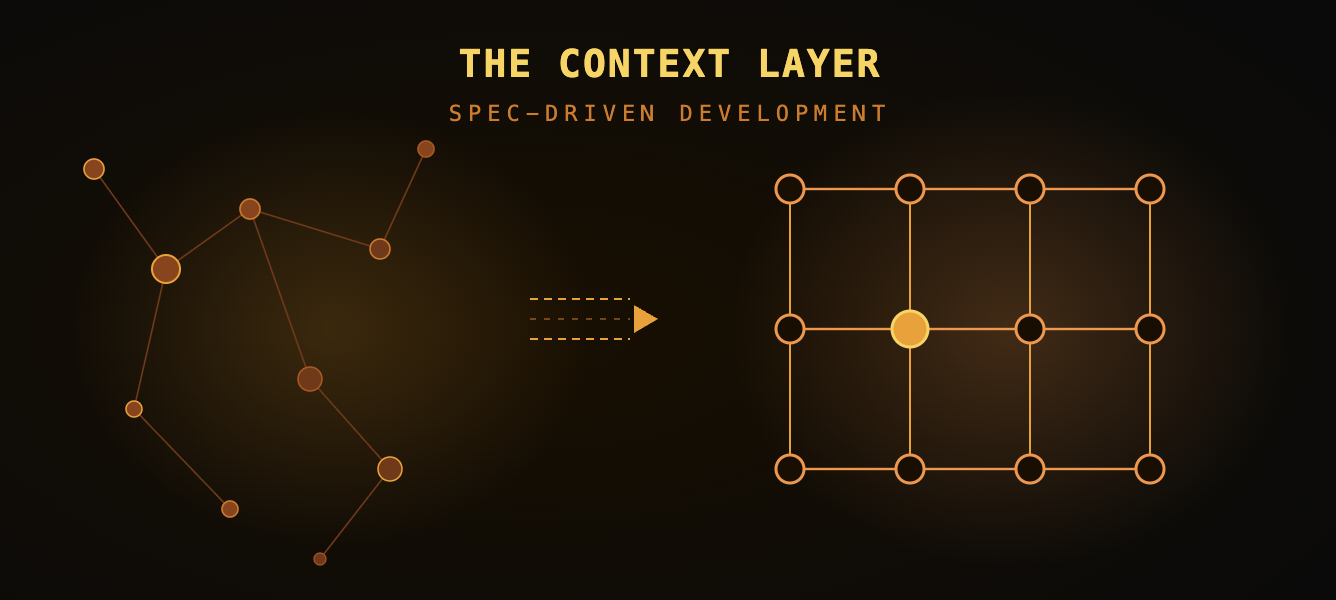
That’s the role of the context layer.
The context layer takes fragmented system data and turns it into a usable model of the process by connecting work across tools, normalizing differences between teams, and mapping execution back to intent. In more practical terms, it creates a shared language across the SDLC. Until you have that, everything built on top is guesswork with better visuals.
Once the process is represented properly, two things change at once.
For the humans running it, the conversation shifts. You stop debating what might be happening and start seeing where work is actually getting stuck, where it’s moving backward, and where teams are quietly skipping steps to keep things moving.
For the agents operating inside it, you can now give them something they’ve never had: structured, high-fidelity specs grounded in real process state. You’re working from specs that reflect how the work is actually supposed to happen—what was agreed, what’s changed, and what constraints matter. This is what makes spec-driven development possible.
This is the part that tends to make people uncomfortable. Defining what you want to build has always been the hardest part of software development.
Human developers have been able to compensate for that. They ask questions, fill in gaps, and course-correct when something feels off. Agents don’t do that. They take the spec you give them and execute.
So spec-driven development isn’t a new problem created by AI. It’s the oldest problem in software, and it’s no longer possible to ignore. The SDLC stops being a black box the moment you stop relying on explanations to understand it.
For years, this was an efficiency problem. Now it’s a gating factor. If you want AI to operate inside your development process instead of just generating output on the edges, you need a system that reflects how that process actually works.
An AI agent tasked with helping ship a feature faster still needs to see how requirements changed, where work is stuck, whether testing was completed, and which steps were skipped. Without that, it can’t improve the process—it can only produce more output inside the black box.
Without that foundation, AI is just another layer producing confident guesses. With it, you can start to trust what it’s doing. That’s the difference between acceleration and noise.
If you don’t have a clear, shared representation of your process, you don’t understand it. And if you don’t understand it, adding AI will just make the problem impossible to ignore.

